AI 数据中心中的网络损伤
AI 数据中心是现代 AI 工作负载的核心,支持着规模日益庞大的模型训练,它依赖复杂且同步的数据交换。尽管网络基础设施为这些操作提供支撑,但常常承受巨大的压力,成为性能提升的瓶颈。
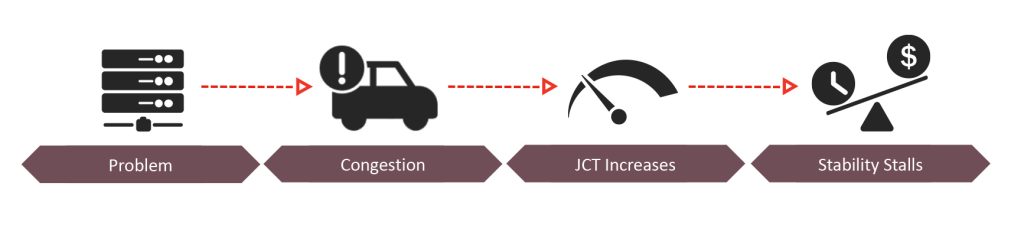
例如拥塞、丢包和流量冲突等网络损伤会导致延迟,进而拉长任务完成时间JCT(job completion times)。在这些损伤中,有一种损伤对 AI 工作负载效率的影响尤为明显,它就是尾延迟(Tail Latency)。
限制网络性能的瓶颈可能以多种形式存在,但尾延迟尤其棘手。因为它会阻碍关键数据流,浪费 GPU 资源,并限制系统可扩展性。
本篇博文,我们来探讨尾延迟、解释其在 AI 数据中心中的重要性,以及应对方法。
什么是尾延迟?
尾延迟指系统中最慢的数据传输或数据包所经历的延迟。与关注平均延迟不同,尾延迟强调的是延迟分布中“尾部”的极端延迟,通常指数据包传输时间分布中的第 95 至第 99 百分位。
为什么尾延迟是个棘手的问题?
在 AI 数据中心中,AI 训练任务中关键数据流的延迟导致尾延迟成为主要瓶颈。AI工作负载通常采用“全对全”通信(all-to-all communication),即多个GPU 之间必须完成数据交换后,才能继续执行下一阶段。
即使大多数数据准时到达,只要最慢的数据包延迟未到达,整个流程就被迫等待。这种小延迟会不断累积,最终导致任务完成时间(JCT)延长,并降低网络效率。
AI 数据中心中尾延迟的成因:
-
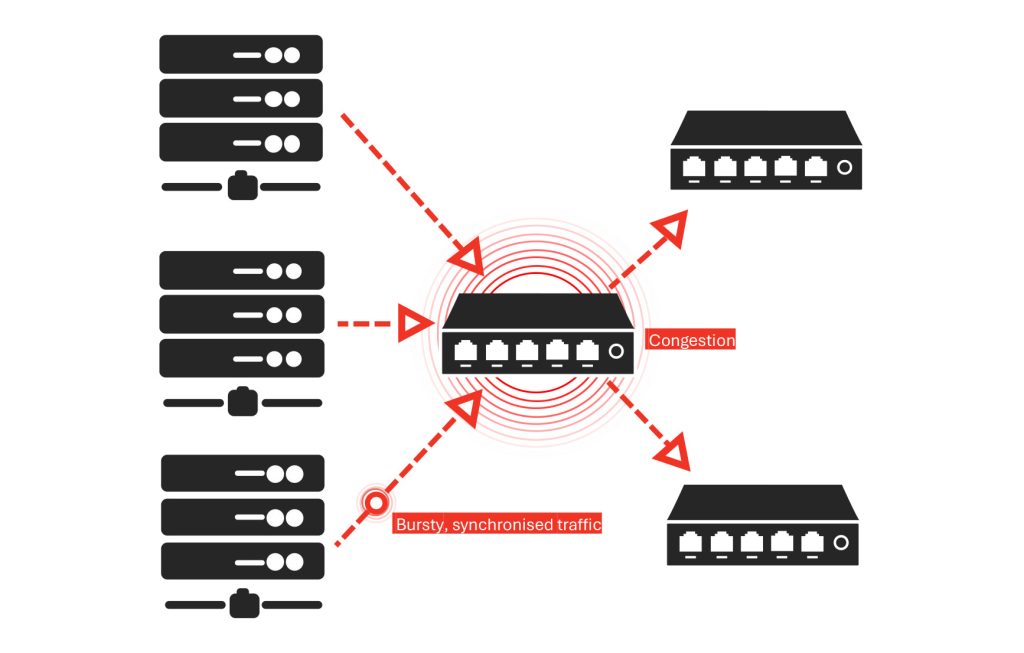
拥塞与瞬时过载(Transient Oversubscription): 同步突发流量压垮网络链路,导致临时性延迟。
-
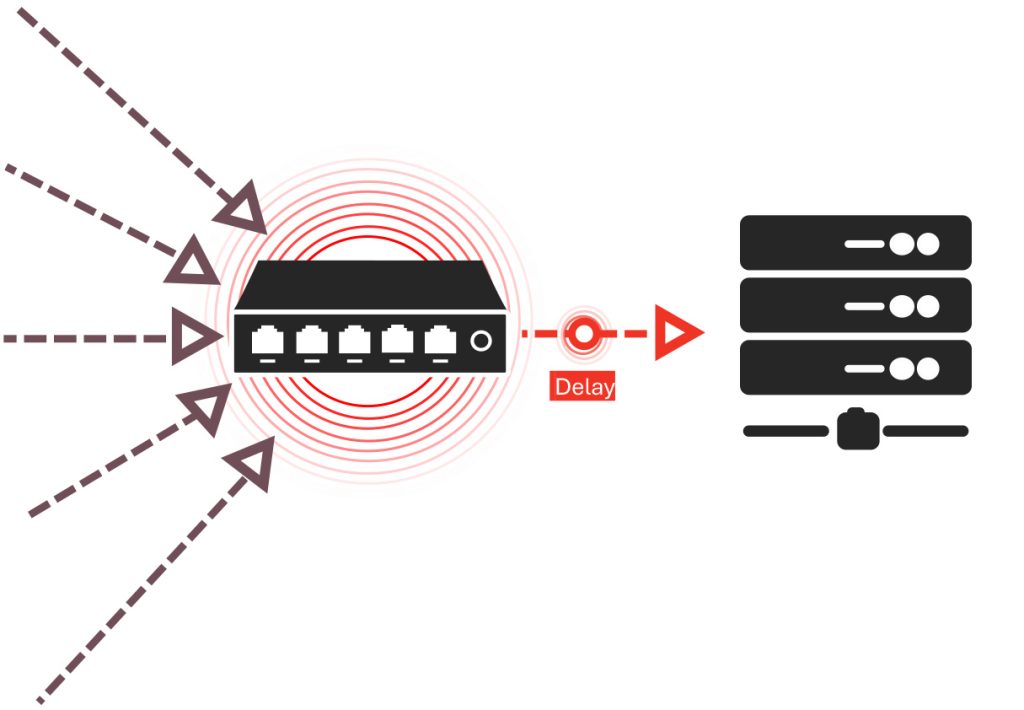
汇聚流(Incast): 过多节点同时向一个目的地发送数据,导致交换机缓冲区不堪重负。
-
丢包与重传: 丢包会触发重传,造成额外延迟并打乱工作流程。
-
抖动与不稳定性(Jitter and Variability): 不一致的网络状况引起数据包传输延迟波动,加剧尾延迟。
-
流量冲突(Flow Collisions): 多条竞争流共享网络路径,导致关键数据包传输受阻。
尾延迟对 AI 性能的影响
尾延迟对 AI 训练任务具有极大的影响:
-
作业完成时间(JCT)增加:进程需等待最后一个数据包到达,进而拖延整体任务时间。
-
GPU 资源浪费: GPU处于空闲状态,等待迟到的数据包,而无法进行有效计算。
-
可扩展性受限:随着 AI 模型规模的扩大,网络延迟随之增加,限制资源地有效扩展。
简而言之,尾延迟会拖慢进度、浪费资源并降低投资回报率(ROI)。这些都是数据中心运营者无法忽视的关键问题。
如何应对 AI 数据中心中的尾延迟
有效降低尾延迟的关键方法之一,是在真实且可重复的场景下测试和优化网络状况。通过模拟拥塞、抖动(Jitter)、汇聚流(Incast) 等网络损伤,团队可以提前识别性能瓶颈并加以解决,避免其影响工作效率。
缓解尾延迟的四个步骤:
-
复现真实的流量模式:模拟大规模 AI 训练任务中突发的数据流。
-
识别潜在问题场景:在拥塞、丢包和抖动等条件下测试网络行为,找出延迟发生的根源。
-
优化网络性能:实施改进措施,如加强拥塞控制、缓冲区调优和优化网络拓扑结构。
-
在受控环境中验证优化效果:持续在仿真环境中测试网络优化方案,确保网络在 AI 高峰负载下的可靠性。
尾延迟只是 AI 网络优化中的一部分。AI 数据中心还面临丢包、链路故障和过载(Oversubscription)等问题,这些都可能影响性能。
通过了解和解决尾延迟问题,将为构建满足现代 AI 工作负载需求的可扩展网络基础设施打下坚实基础。
在下一篇博客中,我们将探讨如何重建真实的 AI 网络环境,以实现更高效的测试与优化——帮助您在可控、可重复的环境中应对尾延迟及其他网络挑战。






")
")
——真实的需求还是伪需求?| 空口测量OTA系列博客(3)")


与数据中心")
您的5G VNF将如何在“云”中工作?")
部署前的洞察力——数据中心工程师验证工作必备")


同步测试5G网络")





 :在同步领域,我们将面对怎样的新挑战?")






时钟标准")
















在前传中测试同步")

前传中的同步方法")
前传Fronthaul网络的同步要求")
")
")
 | 前传系列 (1)")




